Exporting via the REST API
Want to test the REST API?
Navigate to our interactive documentation to try out the REST API here
This page describes how to create an export using the REST API. This might be useful, if you want to automatically create documentation with every nightly build. For more information about using the REST API in Confluence see: Using the REST APIs.
All Scroll Exporter are supporting the REST API. By using the REST API, you can automatically start your exports. For example, you can do an export with every nightly build.
Info
If you want to create an export of thousands of pages, please have a look at the page How Can I get the REST URL before Export?. You should also consider using the asynchronous API in this case.
Before you begin: Before getting the URL, you have to export your content to HTML.
Getting the URL
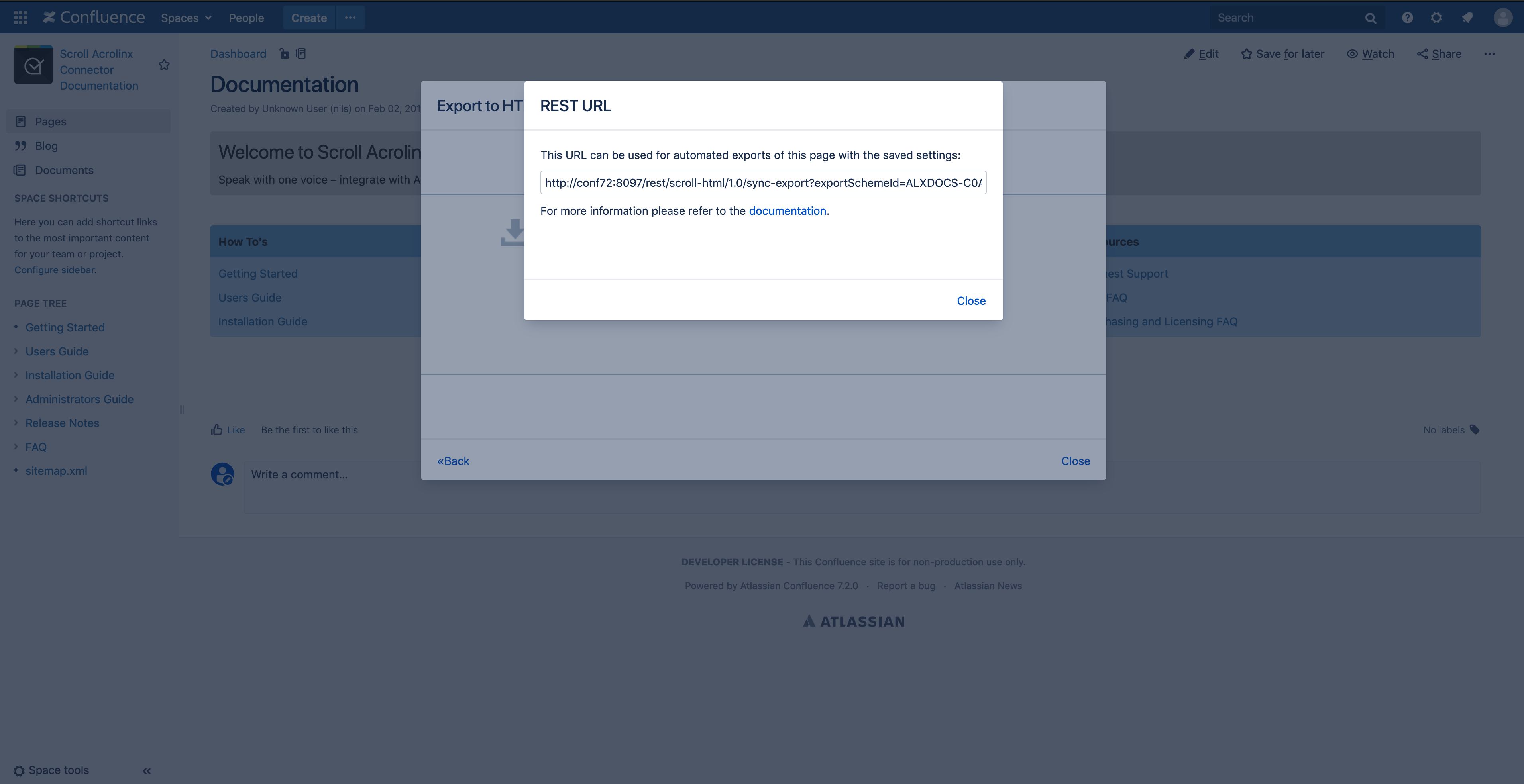
Confluence Administrators and Space Administrators require access to the REST URL which can then be inserted into a script.
To get the URL:
- Click Page Tools (•••) > Export to HTML.
The screen Export to HTML and the existing export schemes are displayed. - Select the wanted export scheme and click Start Export.
The progress bar is displayed. - Click REST URL, copy the displayed URL and click Close.
The REST URL is copied and can now be used in your script, see the curl and wget examples below.
Using the URL
The URL can be used with different tools.
Authentication
You can authenticate yourself for the REST APIs in three ways.
Basic HTTP authentication offers the best password security
We recommend using the basic HTTP authentication protocol, as it offers the best password security. Please note, in Confluence 7.12 (and later) Atlassian plans to let admins disable basic authentication (see section 'Changes to basic authentication' here) and our REST API does not support Atlassian's new approach for using personal access tokens instead. This means that if Basic Authentication is disabled it will not be possible to use the REST API with Scroll PDF Exporter.
- Log in to Confluence manually You will then be authenticated for the REST APIs for that same browser session.
- Use HTTP basic authentication (Authorization HTTP header) containing 'Basic username:password'.
 username:password must be base64 encoded. The URL must also contain the 'os_authType=basic' query parameter.
username:password must be base64 encoded. The URL must also contain the 'os_authType=basic' query parameter. Using URL parameters You may specify your username and password in the URL using the 'os_username' and 'os_password' parameters. The user credentials in the URL do not need to come from the admin – they can be from any user with view permissions for the space.See below for examples.
Using Confluence 7.10 or later?
Please note that since Confluence 7.10, Atlassian has introduced changes that will affect those who authenticate themselves using query parameters (see section 'Seraph upgrade' here). As a result, authentication using URL parameters will not work by default. Therefore, if you're relying on theos_username+os_passwordquery parameter, you'll need to add theatlassian.allow.insecure.url.parameter.login=truesystem property in your Confluence instance.
If you want to use some non-browser tool like wget or curl, you probably have to use either HTTP basic authentication or URL parameters.
curl
Curl is a command line tool for transferring data with URL syntax. It is preinstalled on MacOS X and available for all Linux distributions using the package manager. There are also builds for Windows available.
You can use curl using the command line as follows. On MacOS X and Linux please make sure to place the URL in double quotes as otherwise the "&" character inside the URL will break the command.
HTTP basic authentication:
curl --remote-header-name --remote-name -u admin:admin "http://www.example.com/confluence/rest/scroll-html/1.0/sync-export?exportSchemeId=7F00000101316644174326E600DED2BA&pageId=32769&os_authType=basic"URL parameter based authentication:
curl --remote-header-name --remote-name "http://www.example.com/confluence/rest/scroll-html/1.0/sync-export?exportSchemeId=7F00000101316644174326E600DED2BA&pageId=32769&os_username=admin&os_password=admin"Note
In some cases the colons are replaced with '&3A'. Please check the permalink carefully and edit it if necessary.
If you want to call curl from a script, the "-f" parameter may be interesting as it will make curl return some non-zero return value in case of download errors. See the curl documentation for more info.
wget
wget is another command line tool for transferring data with URL syntax. It is available for all major platforms.
You can use wget using the command line as follows. On MacOS X and Linux please make sure to place the URL in double quotes as otherwise the "&" character inside the URL will break the command.
HTTP basic authentication:
wget --content-disposition --http-user=admin --http-password=admin "http://www.example.com/confluence/rest/scroll-html/1.0/sync-export?exportSchemeId=7F00000101316644174326E600DED2BA&pageId=32769&os_authType=basic"URL parameter based authentication:
wget --content-disposition "http://www.example.com/confluence/rest/scroll-html/1.0/sync-export?exportSchemeId=7F00000101316644174326E600DED2BA&pageId=32769&os_username=admin&os_password=admin"Other Tools
If you use other tools, you can compose the URL as described below.
HTTP basic authentication:
[http://www.example.com/confluence/rest/scroll-html/1.0/sync-export?exportSchemeId=7F00000101316644174326E600DED2BA&pageId=32769&os_authType=basic]URL parameter based authentication:
[http://www.example.com/confluence/rest/scroll-html/1.0/sync-export?exportSchemeId=7F00000101316644174326E600DED2BA&pageId=32769&os_username=admin&os_password=admin]
Asynchronous Export
Sometimes it might be necessary to asynchronously trigger the export. We recommend to use this API if you want to expect a large number of pages.
While this script is not officially supported, you may use the example bash-script linked below.
To asynchronous export your content:
- Download the example bash-script.
- Open the bash-script with a text-editor.
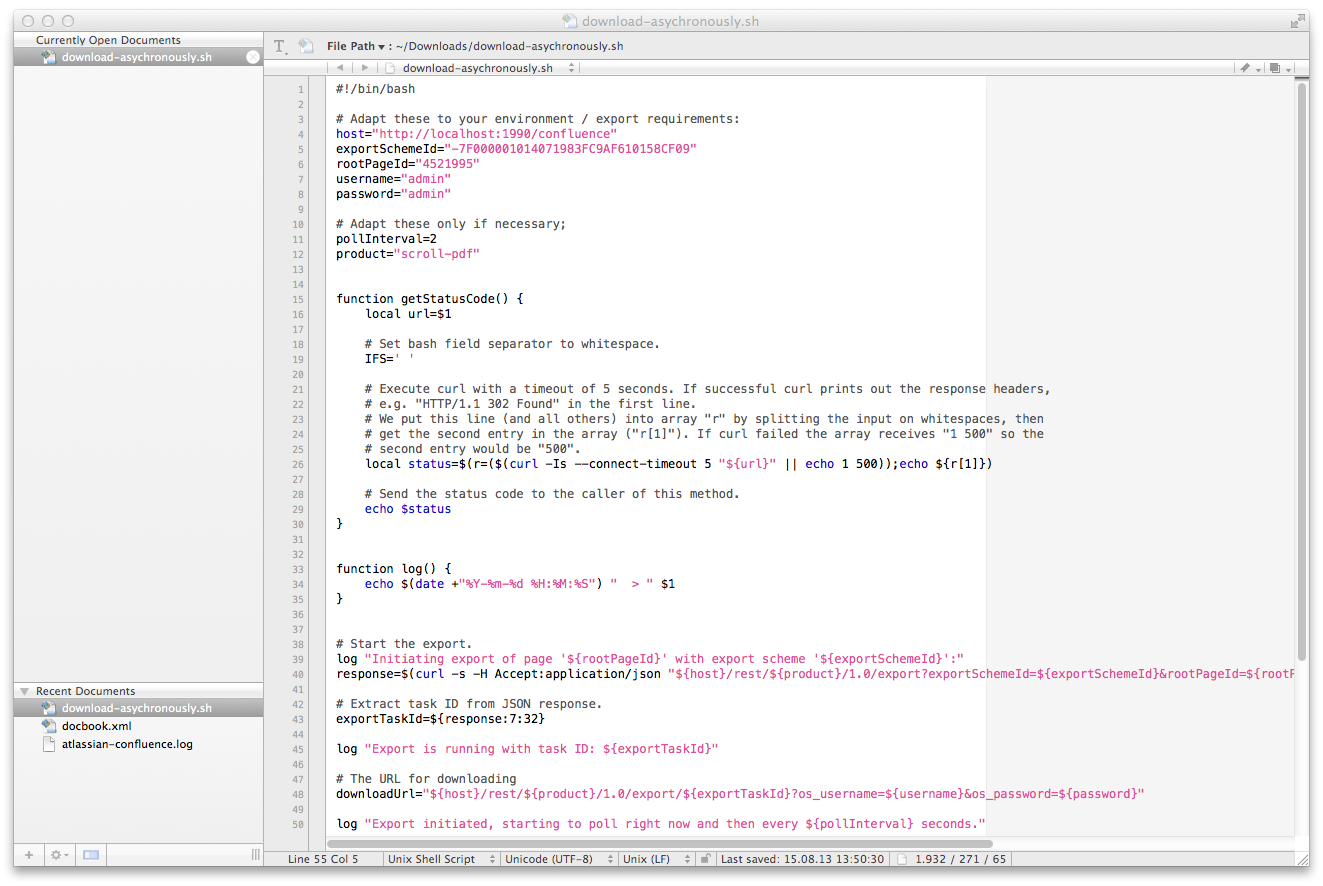
Edit the following values:
Value Description hostEnter your Confluence server URL. exportSchemeIdEnter the exportSchemeId. rootPageIdEnter the Id of the page you want to start the export from. usernameEnter the username of the user performing the export. passwordEnter the password of the user performing the export. productEnter the plugin-key of your exporter:
scroll-html
versionId
This value only works when Scroll Versions is also activated in the space
Enter the Id of the version you would like to export
variantId
This value only works when Scroll Versions is also activated in the space
Enter the Id of the variant you would like to export.
Or use variantId=all for all variants.
- Save the file
You can now use this script to automatically start your exports.
Exporting without saved Export Scheme
You can also perform an export without saving an Export Scheme first. This is helpful if you do not want the specific Export Scheme to appear on the Confluence UI, or if your export settings are generated dynamically.
This works by POSTing the Export Scheme data to the export REST endpoint, instead of specifying a saved Export Scheme.
To do that:
Preparing the Export Specification File
The Export Specification File must be stored in JSON format and must contain the root page of the export, the Export Scheme data and (optional) details from Scroll Versions / Scroll Translations to export the correct version, variant, or language.
To prepare the Export Specification File:
- Create a temporary Export Scheme with your settings and save it for now.
- Get the ID of the temporary Export Scheme from the REST URL as described in the get.
Download the Export Scheme as file using the following curl command:
Download export-scheme.json
CODEcurl -H "Accept:application/json" "http://localhost:1990/confluence/rest/scroll-html/1.0/export-scheme/-C0A81178014CC162A59E7BAB1D2F8FBA" --output export-scheme.jsonIf you do not need the temporary Export Scheme, delete it.
Create your Export Specification File as a new text file with the following content:
export-spec.json (template)
CODE{ "rootPageId": "<ROOT_PAGE_ID>", "versionId": "<VERSION_ID>", "variantId": "<VARIANT_ID>", "languageKey": "<LANGUAGE_KEY>", "exportScheme": <EXPORT_SCHEME_DATA> }- Enter the details in this file:
- Replace <ROOT_PAGE_ID> with the ID of the Confluence page that your export should start on.
 This is required.
This is required. - Replace <VERSION_ID>, <VARIANT_ID> and <LANGUAGE_KEY> with the respective values from the REST URL. All of these fields are optional. If you don't need them remove the respective lines.
- Replace <EXPORT_SCHEME_DATA> with the contents of the export scheme file. This is required.
- Replace <ROOT_PAGE_ID> with the ID of the Confluence page that your export should start on.
export-spec.json (example)
{
"rootPageId": "10158113",
"versionId": "AE5345ASFD3231",
"variantId": "CF34B56543AED1",
"languageKey": "en",
"exportScheme": {
"id": "C0A81178014CC162A59E7BAB1D2F8FBA",
"name": "My temporary Export Scheme",
"pageSelectionStrategy": { ... },
"pageBuilder": { ... },
"exporter": { ... },
"exportAdhocPublishedOnly": false
}
}Performing the Export
Use curl to perform the export and specify the Export Specification File to upload using the following curl command:
curl -H "Content-Type:application/json" --data-binary @/path/to/export-spec.json --remote-header-name --remote-name -u admin:admin "http://localhost:1990/confluence/rest/scroll-html/1.0/sync-export?os_authType=basic"This posts the data from the referenced Export Specification File to the REST endpoint and performs the export with these settings.
It is also possible to POST this data to the asynchronous REST API.